Javascript es un lenguaje de programación interpretado, multiparadigma: funcional, imperativo y basado en prototipos.
Historia y peculiaridades
Javascript fue creado en NetScape con la intención de incluir dinamismo al navegador, a pesar de que al principio solo eran popups esta idea intentó ser copiada por otros navegadores, como Internet Explorer con JScript. Pero finalmente JavaScript fue estandarizado por la organización ECMA y los otros perdieron la batalla.
Javascript estaba pensado para diseñadores, por lo cual hay algunas peculiaridades en el lenguaje. Peculiaridades como que la igualdad de una expresión con su negación resulta verdadera, o la igualdad de un dato de distinto tipo da a su vez como verdadera:
[ ] == ![ ]
>> true
Explicación: Lo que se está igualando, es la referencia en memoria del array. Por tanto no es igual
2 == “2”
>> true
Explicación: El operador “==” convertirá los dos operandos en el mismo tipo para luego compararlos, lo que resulta en positivo
Algunas de estas peculiaridades son apropósito para hacer el código más sencillo de leer a los diseñadores de páginas.
Runtime Javascript
Cuando queremos ejecutar y crear código Javascript, realmente no debemos instalar nada ya que este código se ejecuta en el navegador y el navegador se encarga de ejecutarlo por nosotros.
Pero, ¿Cómo funciona esto exactamente?
Un motor es lo que permite que podamos escribir código humanamente legible y luego este se encarga de que pueda ser procesado por el computador. El problema es que para Javascript hay múltiples motores por ejemplo, V8 es el motor de Google Chrome, SpiderMonkey es el motor de Firefox entre otros.
Los motores deciden cómo ejecutar el código que los desarrolladores escriben, y para ello en mayor o menor medida implementan el estándar de ECMAScript. ECMAScript solo es un estándar y Javascript es una implementación de ese estándar. Los navegadores, entonces, pueden usar ECMAScript Los navegadores, entonces, pueden usar ECMAScrip como una base sobre cómo interpretar y ejecutar el código Javascript.
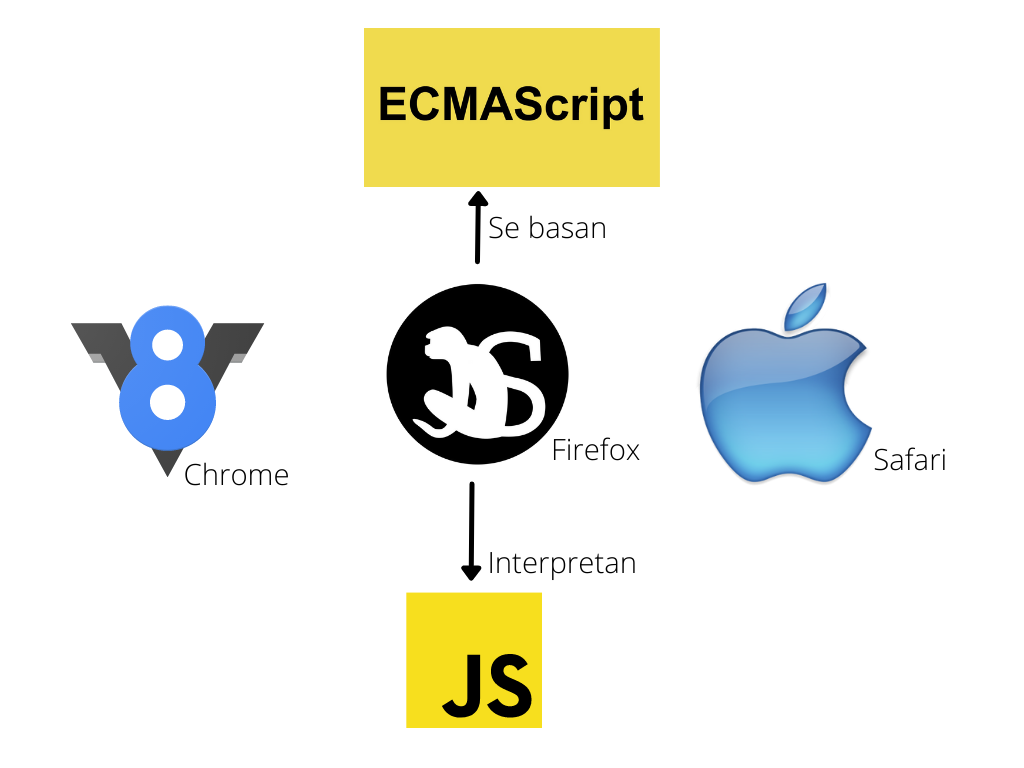
El navegador es el que contiene el motor de Javascript, en ese caso el navegador se le conoce como entorno. Un entorno es básicamente donde está siendo ejecutado el código y el motor hace parte de dicho entorno, por ejemplo JRE o el entorno de ejecución de Java.
Ahora, en teoría deberíamos poder tomar ese motor y colocarlo en un entorno distinto al navegador, y esto es Node.js, un entorno para ejecutar Javascript en el lado del servidor. Node.js usa el motor de Chrome, V8.
Nota: Si Javascript está siendo interpretado o compilado depende del motor que lo esté ejecutando.
Ahora, veamos como funciona un motor de Javascript tomando como ejemplo a V8.
Un motor contiene dos componentes principales:
Memory Heap: Aquí ocurre la asignación de memoria.
Call Stack: Es una estructura dinámica de datos de tipo LIFO que almacena las funciones de la aplicación.
Call Stack: La pila de llamadas, es un almacén de las funciones en la aplicación. Ojo: que deben ser llamadas las funciones para poder ser apiladas.
La pila de llamadas debe tener alguna estructura para poder administrar los frames, es decir, las funciones entrantes y ejecutarlas en un orden apropiado. Esta estructura es LIFO: Last In, First Out, el último en entrar es el primero en salir. La última función que entre será la primera en ejecutarse.
Veamos un ejemplo para comprenderlo mejor.
La pila de llamadas se verá así:

Ahora, en Javascript hay por defecto una función llamada “anonymous” la cuál contiene todo el código que se escriba en el archivo, por lo cuál está será la primera función en entrar y por tanto la última en salir.
A la vez que se ejecuta el código estamos guardando información, y debemos asignar memoria a ello. Cuando le asignamos a una variable un valor el motor de Javascript asigna memoria a la variable, la región en memoria donde se guardaran los datos se llama heap.
Asincronía en Javascript
La asincronía es una parte fundamental del desarrollo en Javascript, pero debemos comprender dos conceptos antes de irnos a ello.
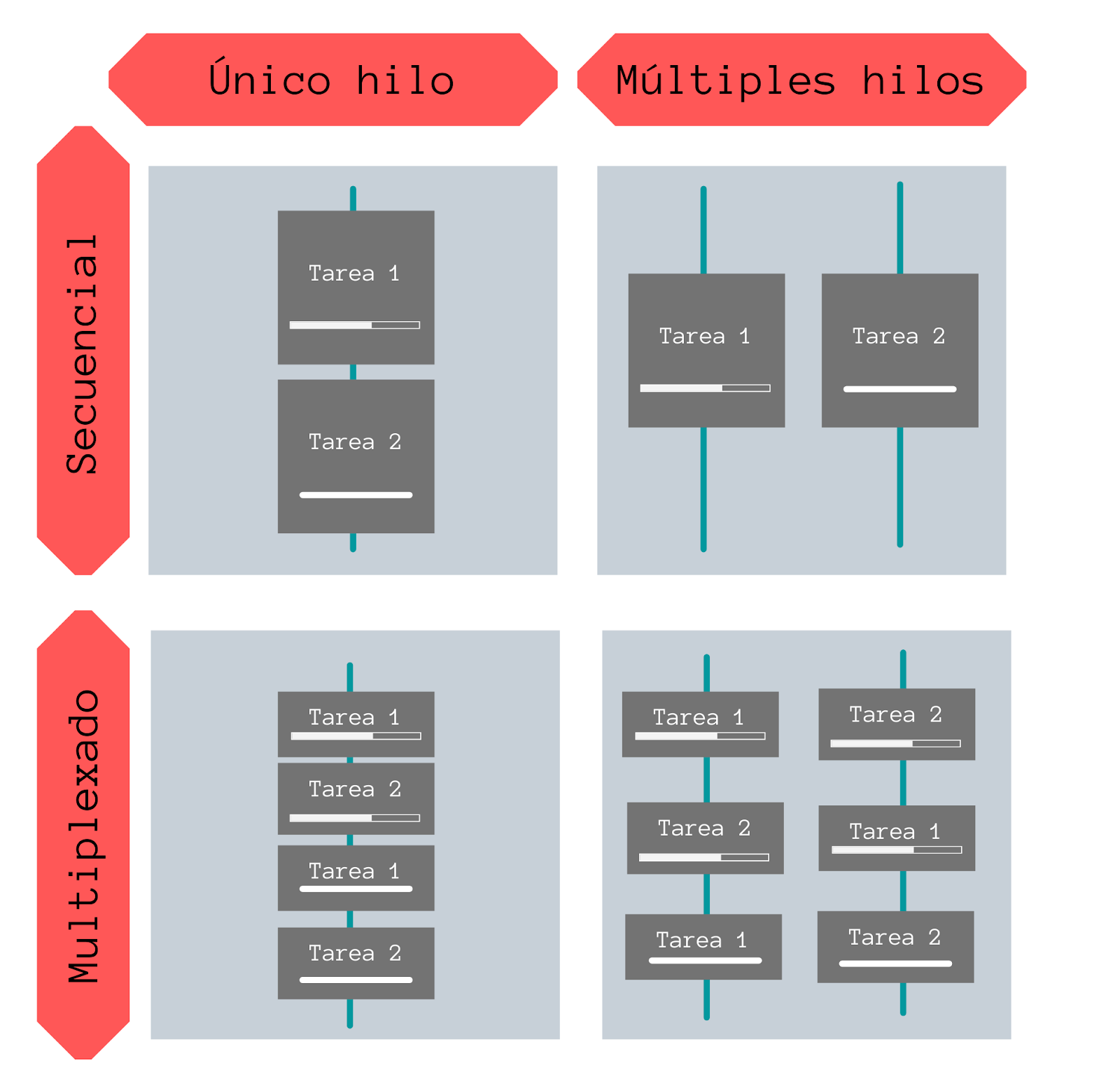
Concurrencia y paralelismo, la concurrencia es cuando dos tareas progresan al mismo tiempo mientras el paralelismo (que es un sub-caso de la concurrencia) ejecuta dos tareas al mismo tiempo. Nótese la diferencia, que dos tareas progresen al mismo tiempo no significa que se ejecuten al mismo tiempo, en la concurrencia solo se tiene un hilo de ejecución y por tanto se pueden utilizar técnicas como el multiplexado para dividir el tiempo y ejecutar las tareas en dichas divisiones de tiempo dando la ilusión de paralelismo, pero al final es solo un hilo de ejecución.
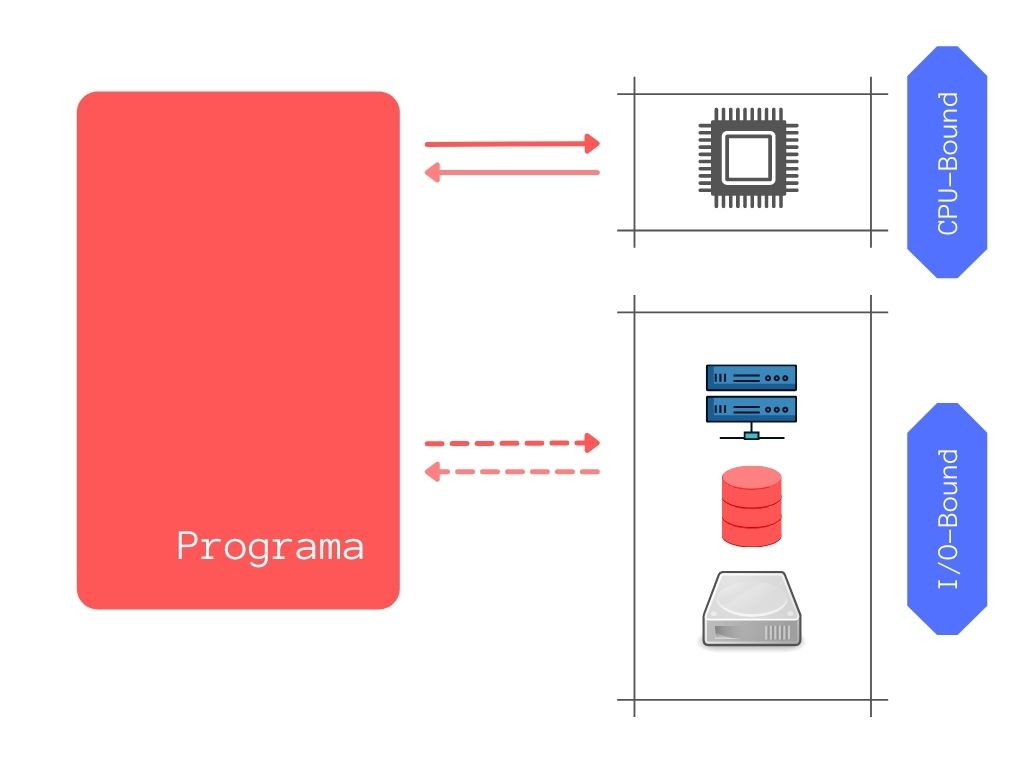
Operaciones CPU-Bound vs I/O-Bound:
En los ejemplos anteriores encontramos tareas que consumen recursos de CPU, a estas se les conoce como tareas limitadas por CPU o CPU-Bound.
Sin embargo, es frecuente encontrar otro tipo de operaciones en los programas, como leer un archivo en el disco, acceder a una base de datos externa o consultar datos de una red. Todas estas peticiones de entrada y salida son atendidas fuera del contexto de la aplicación, por ejemplo para la lectura de un archivo en disco se involucran el sistema operativo y dicho disco en la petición. Por lo tanto las operaciones limitadas por entrada/salida o I/O Bound, no se ejecutan en el dominio de aquella aplicación.
Las operación CPU-Bound son intrínsecamente síncronas o secuenciales (a menos que se utilicen técnicas de multiplexado), pero las operaciones I/O-Bound pueden ser asíncronas, y la asincronía es una forma muy útil de concurrencia.
Clasificación operaciones I/O:
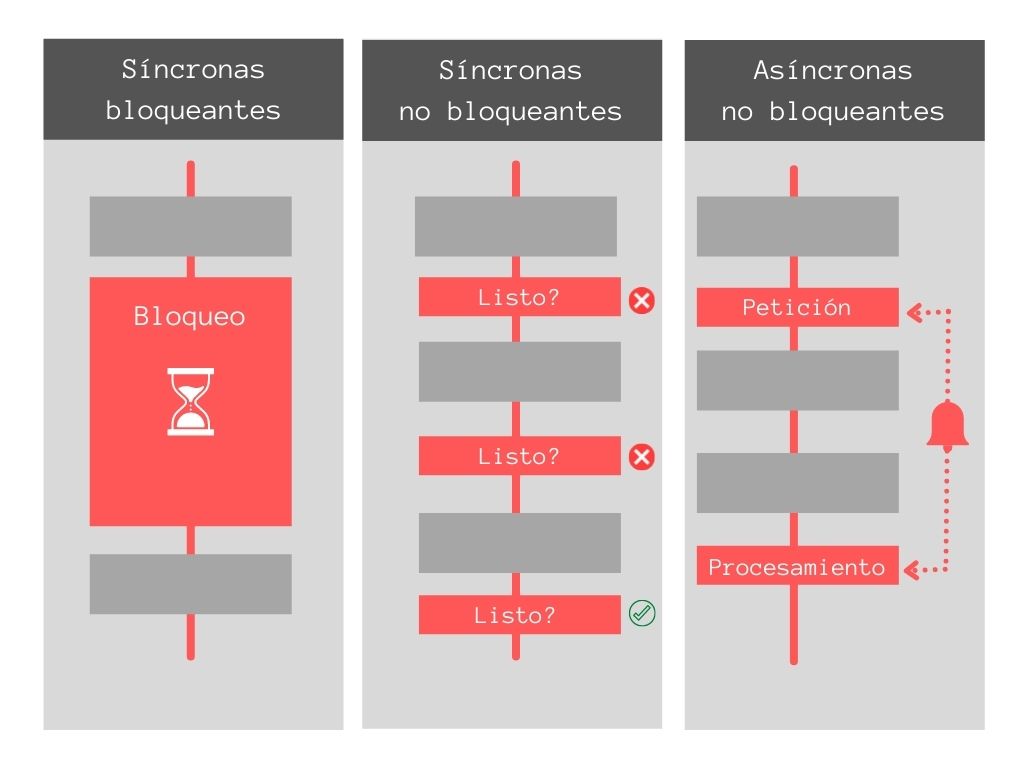
Síncronas y bloqueantes:
Toda la operación se hace de una sola vez, deteniendo el hilo de ejecución.
La respuesta se procesa inmediatamente después de terminar la operación.
Síncronas y no bloqueantes:
Similar a la anterior, pero se utilizará una técnica llamada polling que consiste en preguntar constantemente el estado de la operación, esta misma técnica permite que el hilo de ejecución no sea bloqueado.
La respuesta se procesa inmediatamente después de terminar la operación.
Asincronas y no bloqueantes:
La petición retorna inmediatamente para evitar un bloqueo.
Se envía una notificación una vez la operación haya terminado, y justo allí la función que procesa la respuesta (callback) se encola para ser ejecutada.
Modelo de asincronía en Javascript
Por su origen dentro de los navegadores, Javascript trabaja comúnmente con peticiones de red al mismo tiempo que con las interacciones del usuario. Dado esto, Javascript ha evolucionado pensando en las operaciones de tipo I/O, por esta razón utiliza un modelo asíncrono y no bloqueante, un mecanismo llamado Event loop encargado de peticiones I/O de un único hilo permite a Javascript ser altamente concurrente a pesar de ser de un único hilo.
El funcionamiento del Event Loop es el siguiente:
Petición de operación I/O, se retorna inmediatamente y sigue la ejecución del programa.
Se procesa la petición fuera del programa.
La petición finaliza y lanza una notificación, la notificación se guarda como mensaje en una cola de mensajes pendientes a ser procesados por el entorno.
Una vez el call stack esté vacío el Event Loop hará un “tick” y enviará el callback a ser ejecutado por el call stack
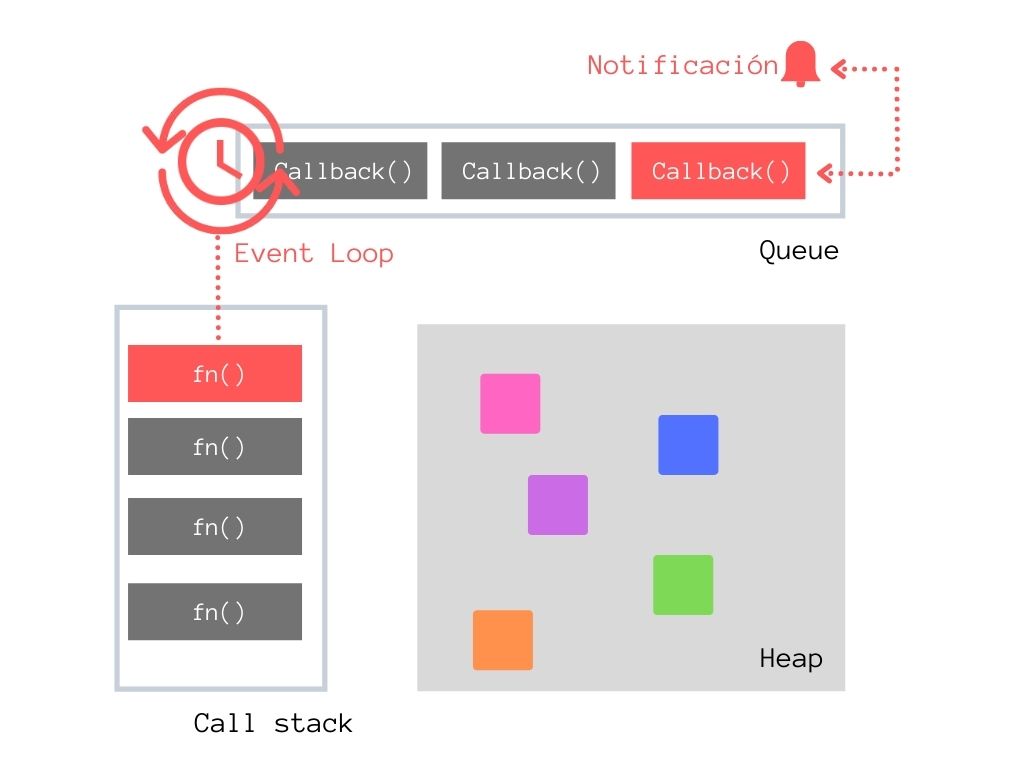

Patrones asíncronos en Javascript
Callback: No es más que una función que se pasa como argumento a otra función, en este contexto el callback será algo como ¿Qué quieres hacer una vez termine la operación asíncrona finalice?. Por tanto una vez la operación asíncrona notifique que ha finalizado el callback será ejecutado. Ejemplo sencillo de callback:
Recuerda que, para que se ejecute el callback el call stack debe estar vacío.
Promesas: Las promesas se basan en callbacks, pero proveen mayor legibilidad. Este patrón devolverá inmediatamente un objeto Promise cómo garantía de que la operación asíncrona finalizará en algún momento y devolverá un valor, ya sea con fallo o éxito. Al objeto Promise le damos dos callbacks, uno si la operación llegó con éxito y otro si hubo algún fallo.
Las promesas pueden ser encadenadas, esto ya que la llamada then() también es una promesa, además podemos capturar rechazos a cualquiera de las llamadas then() con catch() al final de la secuencia de llamadas then().
Composición del objeto Promise
Es frecuente tener más de una promesa y habitualmente es útil que se ejecuten paralelamente. Es decir, se lanzan varias tareas asíncronas al mismo tiempo y estamos a la espera de que una o todas las promesas se resuelvan. Para ello se cuenta con dos herramientas de gran utilidad, Promise.all() y Promise.race().
Promise.all(), recibe un array de promesas y retorna una nueva promesa una vez todas las promesas del array hayan retornado de manera satisfactoria, o en caso de fallo, será rechazada en cuanto una de las promesas originales sea rechazada. Ejemplo:
Promise.race(), es parecido al anterior, pero la promesa se retornará una vez alguna de las promesas originales sea retornada ya sea exitosa o con fallo.
Crear promesas
Una promesa se crea instanciando el objeto Promise, en el constructor debemos asignar un callback con la carga de la promesa, osea, lo que hará la promesa. Este callback recibe dos argumentos: resolveCallback, rejectCallback. Estructura:
Ejemplo sencillo:
Las promesas son muy útiles para envolver APIs asíncronas que funcionen puramente con callbacks
Asincronía en Promesas
El estándar ECMAScript describe el uso de una nueva cola especial, llamada micro-task queue, dando una mayor prioridad a los callbacks de promesas.
Esta nueva cola es de “alta prioridad” lo que significa que cuando el Event Loop haga tick esta cola será atendida primero.
Async/Await
Surgió como una manera más simplificada y elegante de manejar promesas, la etiqueta async declara cualquier tipo de función (anónimas, de flecha, nombre) como asíncrona. Por otro lado, await debe ser usado solo en funciones asíncronas y esperará (asíncrona y no bloqueante) a que la promesa se resuelva.
async/await sigue siendo una promesa, toda la función async será como el resolveCallback de la promesa del fetch. Una vez se resuelva el fetch, la función async será ejecutada asíncronamente. Si una promesa por await es rechazada, automáticamente la función async será rechazada, en este caso se puede concatenar catch().
Gestión de memoria en Javascript
Los lenguajes de bajo nivel como C, tienen primitivos como malloc() o free() para la gestión de la memoria. Por otro lado en Javascript y otros lenguajes de alto nivel reservan memoria cuando objetos (arrays, variables…) y la liberan “automáticamente” una vez ya no son usados aquellos objetos en el programa, a este proceso se le conoce como garbage collector o recolector de basura.
Ciclo de vida de memoria
Reservar la memoria necesaria.
Utilizarla (lectura, escritura).
Liberar la memoria una vez ya no es necesaria.
El primer y segundo paso es explícito en todos los lenguajes, mientras que en lenguajes de bajo nivel el tercero es explícito en lenguajes de alto nivel es implícito.
Reserva de memoria
Javascript reserva memoria al mismo tiempo que en la declaración de valores.
Usar valores
Usar un valor es leer o escribir en memoria reservada, ocurre al leer o escribir una variable o al pasar un argumento a una función.
Liberar memoria cuando ya no es necesaria
Aquí llega el problema, ya que el decidir cuando la memoria ya no será requerida no puede ser resuelta por un algoritmo y el garbage collector solo es una aproximación a la resolución del problema.
Los algoritmos de gestión de memoria (como garbage collector) se basan en una noción de referencia, se dice que “un objeto tiene referencia a otro si el primero tiene acceso al segundo (implícita o explícitamente)”, por ejemplo, un objeto guarda referencia a su prototipo (implícita) y a cualquiera de sus propiedades (explícita). El algoritmo más simple de recolección funciona con estas referencias, “un objeto ya no es necesario si no hay ningún otro objeto que lo referencie”.
Su limitación está en los ciclos, supongamos que dentro de una función tenemos dos objetos que se referencian entre ellos, estos no salen del ámbito de la función con lo cuál podrían ser recolectados. Sin embargo, el algoritmo considera que están referenciados y por tanto siguen siendo necesitados, estos dos objetos crean un ciclo y nunca serán recolectados.
Pero, los ciclos son un problema del pasado. El algoritmo mark-and-sweep (marcado y barrido) determina un objeto innecesario a un objeto inalcanzable. Funciona de la siguiente manera, el algoritmo asume la noción de un grupo de objetos como objetos raíz (en Javascript el objeto global) periódicamente el recolector empezando por la raíz encontrará todos los objetos alcanzables e inalcanzables.